Functional Programming with C#
Scan and FindIndex
This blog article was published as part of the C# Advent 2023 (run by Matthew Groves) for the 18th of December, an honour I shared with fellow Functional Programmer and F# Guru Ian Russell who published an article on Discriminated Unions that you can find here
I've not updated this blog in a while because I've been pretty busy working on my book for O'Reilly Media - "Functional Programming in C#" (available in all good book shops) which was published back in September. I"d hoped to keep this blog going at the same time, but there simply wasn't enough time for me to do both. I'm hoping this will a new start, and hopefully I'll manage to keep to a decent schedule this time.
Introduction
This time I thought I'd treat you to a "deleted scene" of sorts from my book. Or, rather, something I didn't manage to develop as an idea when I was writing the book.
This technique pertains to a definite loop that might need to break early. Just to define terms before we begin:
- Definite Loop: A loop with a specified number of iterations - i.e. a ForEach or For loop
- Indefinite Loop: A loop that iterates until a specified Boolean condition is met - i.e. a While or Do..While loop
A Definite loop is generally implemented in Functional-style C# with a Select statement, where we transform each element of an Enumerable into a new form, but what if that's not precisely what I want? What if I want to reduce an Enumerable down to a single value? There is the inbuilt Aggregate method (of which, more in a minute) but that doesn't cover all potential cases I might want to code. This is where I have to introduce a couple of new methods into LINQ - one that has been available in F# since the beginning - Scan and FindIndex. Used in tandem, these methods can be used to replace While loops in many circumstances.
First, Let's Aggregate
So What's a Scan? It's actually going to take me a whhile to explain, but only a few lines of code to implement. It's similar to the C# Aggregate function (known as a "Fold" in FP parlance). I'll just briefly explain an Aggregate first, since surprisingly few people seem to know about it.
Aggregate is a way of reducing an array of things down to a single thing. Let's work through an example of how it works. A silly example. Let's imagine that for some strange, barking-mad reason I wanted to duplicate all of the letters of the word "Christmas" to make it "CChhrriissttmmaass". No special reason I should, but it'll do for a demonstration.
To aggregate it, I'd start with a seed value - an empty string. The aggregate process iterates through each item in the array (a string is also an array of characters in C#, and indeed many programming languages) and each iteration is supplied with the current running total, and the current item, and from them is expected to make a new running total.
The first iteration has a running total of empty string, and a current item of 'C', and we return 'CC'. The second iteration has a running total of 'CC" and a current item of 'h', and we return 'CC' + 'hh', or 'CChh'. This process continues with each item from the original string, until we've built our final string with every character duplicated. This is what it looks like as a picture:
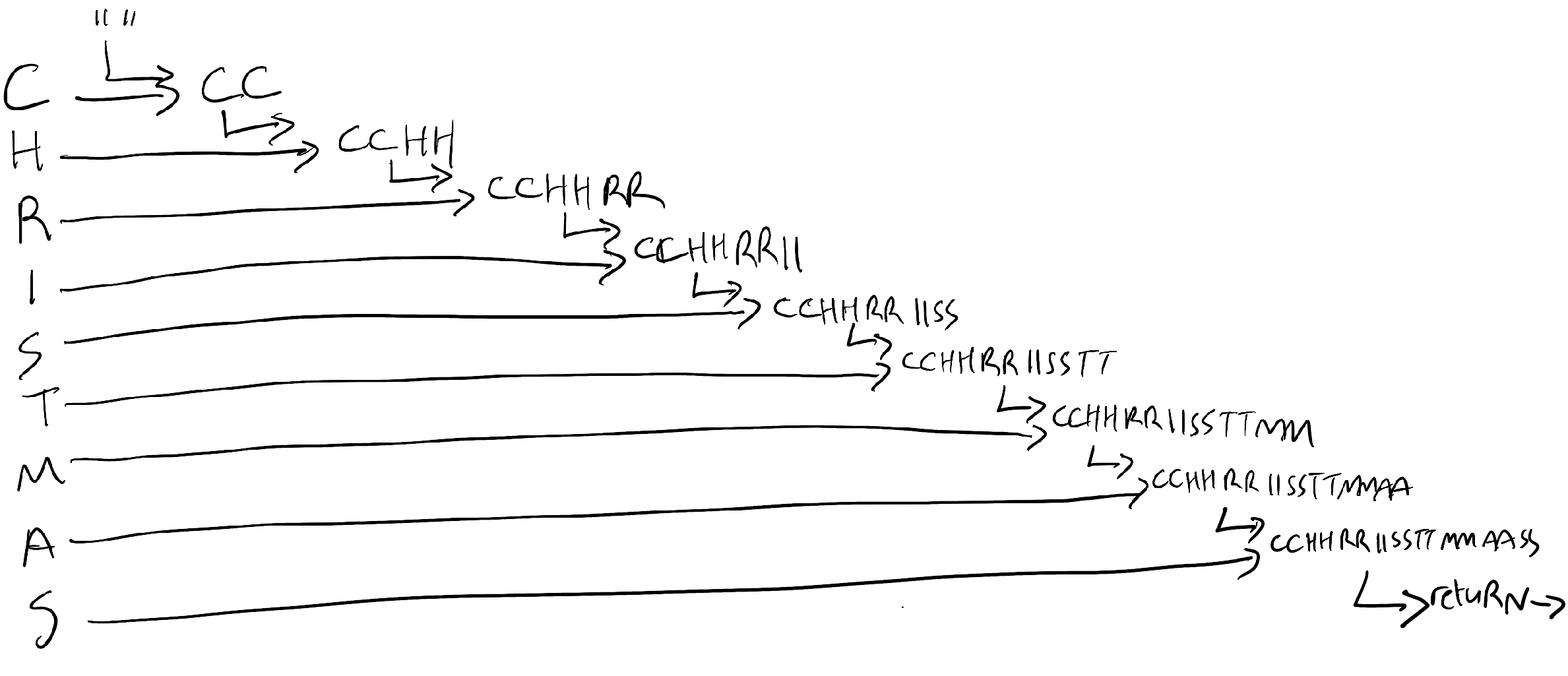
And here is the actual code:
[Fact]
public void Test01()
{
const string input = "Christmas";
var output = input.Aggregate("", (agg, x) =>
agg + x + x
);
output.Should().Be("CChhrriissttmmaass");
}
Right, so that's aggregate. Scan is similar, but with a significant difference. Let me explain....
Scan
So, like Aggregate, Scan takes an Enumerable and iterates through it, while also holding a running total value which updates with each iteration. The big difference though is what is actually produced at the end. Instead of the final, accumulated total, the result is an array of every return from every iteration. You're basically seeing a step by step of how the final total was built. This gives me a chance to indulge in another of my favourite things - the works of legendary British singer-songwriter Kate Bush. Check out this excerpt from one of her better-known music videos:

What you see her doing here is a single movement, but you also see each step of the movement superimposed over each other. If you'd prefer an updated version of my previous illustration of the aggregate to reflect the workings of Scan, then it looks like this:
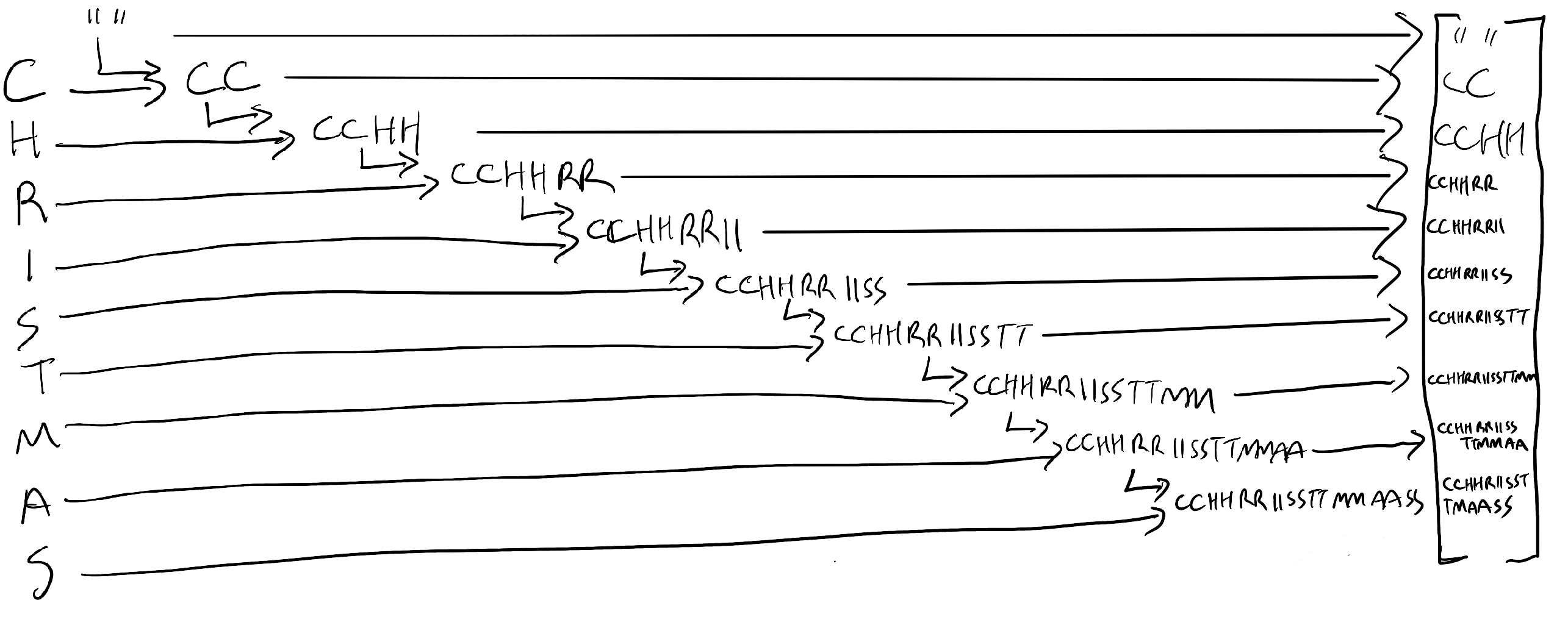
Here's the code to implement your own Scan function:
public static IEnumerable<T2> Scan<T1, T2>(this IEnumerable<T1> @this, T2 seed, Func<T2, T1, T2> acc)
{
var curr = seed;
yield return curr;
foreach (var i in @this)
{
curr = acc(curr, i);
yield return curr;
}
}
If you want you can use it to get the aggregated duplicated character version of "Christmas", like this:
[Fact]
public void Test02()
{
var input = "Christmas";
var output = input.Scan("", (acc, x) => acc + x + x).ToArray();
output.Last().Should().Be("CChhrriissttmmaass");
}
So, what's the point of all this? As you see above, you can get the final aggregated value by taking the last element of the array, but if that's what you wanted you'd be better off using Aggregate instead. What if, though, we wanted to know when a particular state was reached in the process? Let's imagine for a moment that I was asked to build up the string until it was 10 characters long, then stop the aggregation process?
The amazing thing about enumerables - which is what Scan evaluates to - is that they don't actually contain data unless you force them to. They're just pointers to where the data may be found and how to get it until that point. So, my Scan result - until I call ToArray/ToList or run a ForEach is just a set of pointers to code that is only data in potential which means we can apply additional LINQ operations on top of it which will disrupt the flow of enumeration. So if I wanted to get only the first 10 characters of my expanded Christmas string, I only need to do this:
[Fact]
public void Test03()
{
var input = "Christmas";
var output = input.Scan("", (acc, x) => acc + x + x)
.First(x => x.Length == 10);
output.Should().Be("CChhrriiss");
}
Not only does this work, but because the First function breaks enumeration once its condition is met (i.e. the string is of length 10) the remaining iterations of the Scan process are left without being executed. If you want to see that expressed in a unit test, look at this:
[Fact]
public void Test04()
{
var input = "Christmas";
var calls = 0;
var output = input.Scan("", (acc, x) =>
{
calls += 1;
return acc + x + x;
})
.First(x => x.Length == 10);
output.Should().Be("CChhrriiss");
calls.Should().Be(5);
}
Note that the number of times the iteration function is called is only 5 - because we doubled the number of characters each time so 5*2 is 10. The remaining 4 characters of "Christmas" remain unexamined.
There's another extension method we can add as well to get another bit of potential useful information out of the Scan process - FindIndex. Let's look at that now...
FindIndex
FindIndex is similar in some ways to the LINQ function "First", except that instead of getting the actual first item from the Enumerable that meets a condition, we instead just want the index reference to that element. If I were to swap the First in Test03, above it would return the index of the array that resulted from the Scan operation which meets the condition. In this case it would be 5:
[Fact]
public void Test05()
{
var input = "Christmas";
var output = input.Scan("", (acc, x) => acc + x + x)
.FindIndex(x => x.Length == 10);
output.Should().Be(5);
}
Note that it's 5, not 4. The condition is met after the "s" is added to my accumulated string, which was index 4 in the original array (i.e. the input string "Christmas") but in my Scan process, the original seed value "" is also included in the Scan array, since the end condition might have been met before any iterations are done.
I used this technique in one of the very first AdventOfCode puzzles, one that required an array of "(" and ")" characters to update the position of a lift in a giant building. The puzzle was to find the first element in the array that brought the Lift to floor "-1", which is achieved very easily using Scan and FindIndex. If you're interested to see it in action, the puzzle is here and my solution can be found here
Here is the code you need to implement your own version of FindIndex:
public static int FindIndex<T>(this IEnumerable<T> @this, Func<T, bool> cond)
{
var result = @this.Select((x, i) => (x, i)).FirstOrDefault(x => cond(x.x));
return EqualityComparer<T>.Default.Equals(default)
? -1
: result.i;
}
There you have it, very easy to implement, very easy to use. It can also save you a lot of coding and effort when used in the right place.
Conclusion
We've looked at Scan and FindIndex, two extension methods taking inspiration from the library of functions available in F# and not currently in C#. They can be used to convert an array into a series of steps in an iterative process, then to interrupt that process and find a desired state within the flow. It removes the need for something like a ForEach loop with an early return, or anything else within the loop that involves reacting to a variable that's built up over the course of the iteration.
It only remains for me to wish you all a very, very Merry Christmas. It's been a tough few years for us all, and I hope the worst is behind us.
Until next time...
